NASと言ったらBuffaloのイメージが強かったんですが、このSynology NASはもうほとんどただのLinuxパソコンのようで、Webからログインするとデスクトップのような画面が表示されて、そこでパソコンを操作するかのようにNASを管理することができます。また、いろいろなアプリケーションがパッケージセンターに公開されていて、それらをインストールすることで自分好みのNASにしていくことができます。例えばDropboxのように自分の各PC間でデータを同期させたり…。非常に強力なNASで、もはやただのNASというより「自前のクラウド」と言ったほうが良いような代物でした。
ですので、ただのNASとして使って、ひたすらファイルを詰め込むだけじゃなんかもったいないなと思い、Gitサーバーを立ててみることにしました。
準備
- Visual Studio 2017をインストールした環境を2つ以上
- 各PCにGitクライアントをインストール
- Synology NASを使えるようにする
NASの準備
まずはパッケージセンターからGitをインストールします。
次はSSHを有効にしておきます。コントロールパネルの「端末とSNMP」から有効にします。
この設定画面に書いてありますが、Synology NASはadministratorグループに属するアカウントでしかSSH接続できません。何このクソ仕様…。

そしたら次はGit用の共有フォルダを作りましょう。名前は何でもいいですが、今回はGitRemoteにしてみました。

続いてGitアクセス用のユーザーグループを作ります。コントロールパネル→グループで作成します。今回は「gitgroup」にしました。なんでもいいですが、小文字のほうがセンスがあります。
もちろんアクセス権限はGitRemoteフォルダのみに限定して、読み書き両方の権限を与えます。

つづいてユーザーを作ります。今回は「gituser」にしました。例によってなんでもいいですが、小文字のほうがセンスがあります。

グループはgitgroupのほか、administratorに所属させる必要があります。これは外部からSSH接続するためです。

administratorだとデフォルトですべてのフォルダにアクセスできてしまいますので、余計なフォルダへのアクセス権は消しておきましょう。
まあ、administratorなので自身のアクセス権の変更もできてしまうのですが…。

最後にGitを起動し、gituserにアクセス権を与えて準備完了です。

Gitリポジトリの作成
つづいてリポジトリを作成します。SSHでNASに接続して操作をします。ターミナルはSSHがつながればなんでもいいですが、今回はPuTTYを使いました。

ログインしたら作成した共有フォルダ(/volume1/GitRemote)に移動し、リポジトリとなるフォルダを作ります。今回は「TestProject.git」としました。そして、
git --bare init --shared TestProject.git
を実行することで空のGitリポジトリを作成します。
このままでは全ユーザーにアクセス権が与えられてしまいますので、gitgroupに限定しましょう。
chown -R gituser:gitgroup TestProject.git/
chmod -R 770 TestProject.git/
これでグループ内にのみrwxのアクセスが与えられました。 chmod -R 770 TestProject.git/

これでGitリポジトリの作成は完了です。
Visual Studioでプロジェクトを作る
Visual Studioでプロジェクトを作ります。新しいプロジェクトを作る際に「新しいGitリポジトリの作成」にチェックを入れるのを忘れないようにしてください。
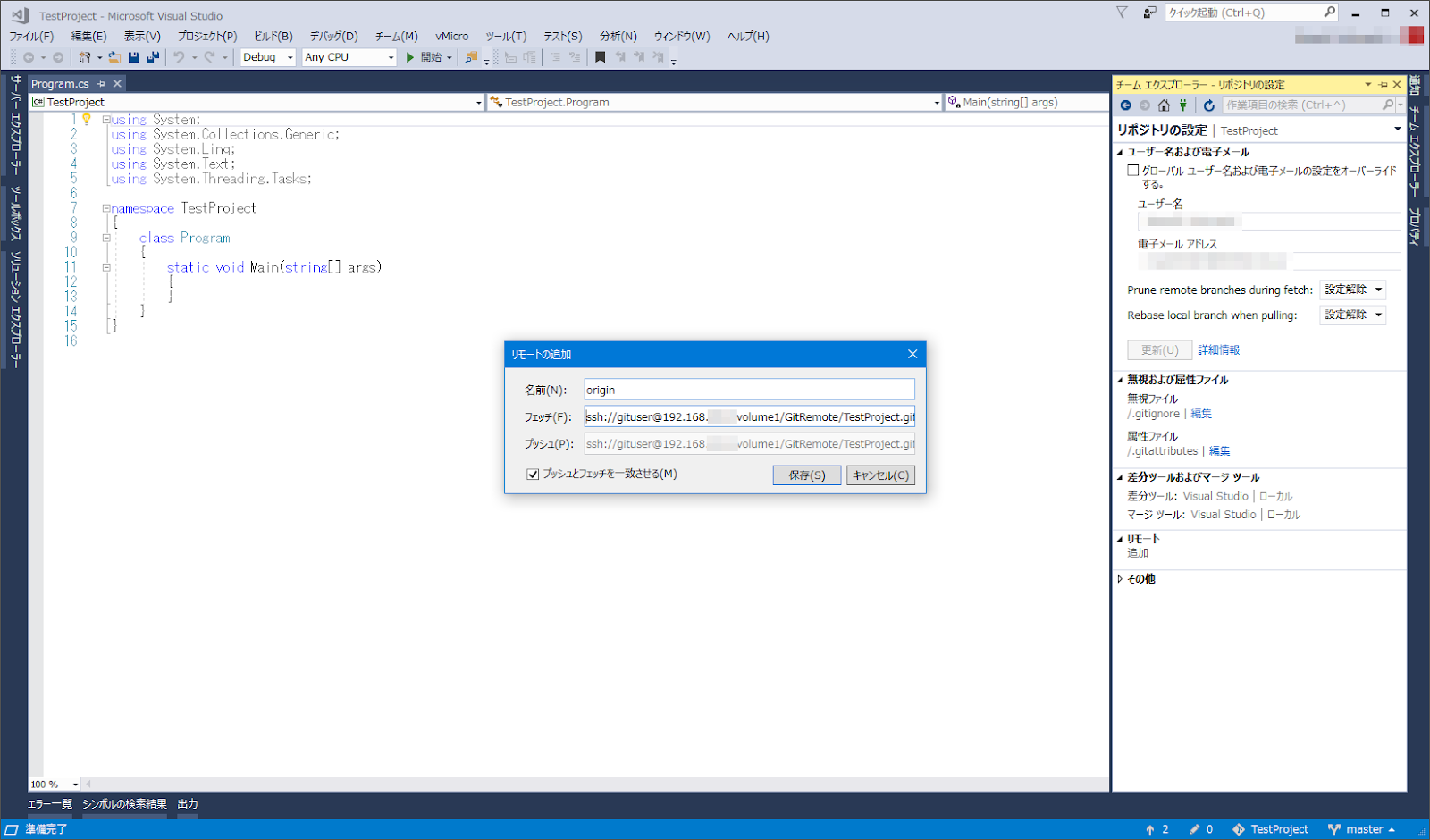
プロジェクトが出来上がったら、「チームエクスプローラー」→「設定」→リポジトリの設定」からリモートの「追加」ボタンを押します。
リモート名はorigin、フェッチ/プッシュはリポジトリのURLを指定します。今回は「ssh://gituser@[NASのIPアドレス]/volume1/GitRemote/TestProject.git」になります。
つづいて「チームエクスプローラー」→「同期」を開きます。
ここにある「プッシュ」ボタンを押せば、先ほど指定したリポジトリにプッシュを行います。

Gitのパスワード入力画面が開くので、ここでgituserのパスワードを指定します。

正常にプッシュされました。めでたしめでたし。

リポジトリからのクローン
別PCでリポジトリをクローンしてみます。
Visual Studioはクローンには対応していない(はず)なので、こればかりはコマンドラインから実行します。Visual StudioのプロジェクトのディレクトリからPowerShellを開き、
git clone ssh://gituser@[IPアドレス]/volume1/GitRemote/TestProject.git
と入力すればリモートリポジトリからクローンします。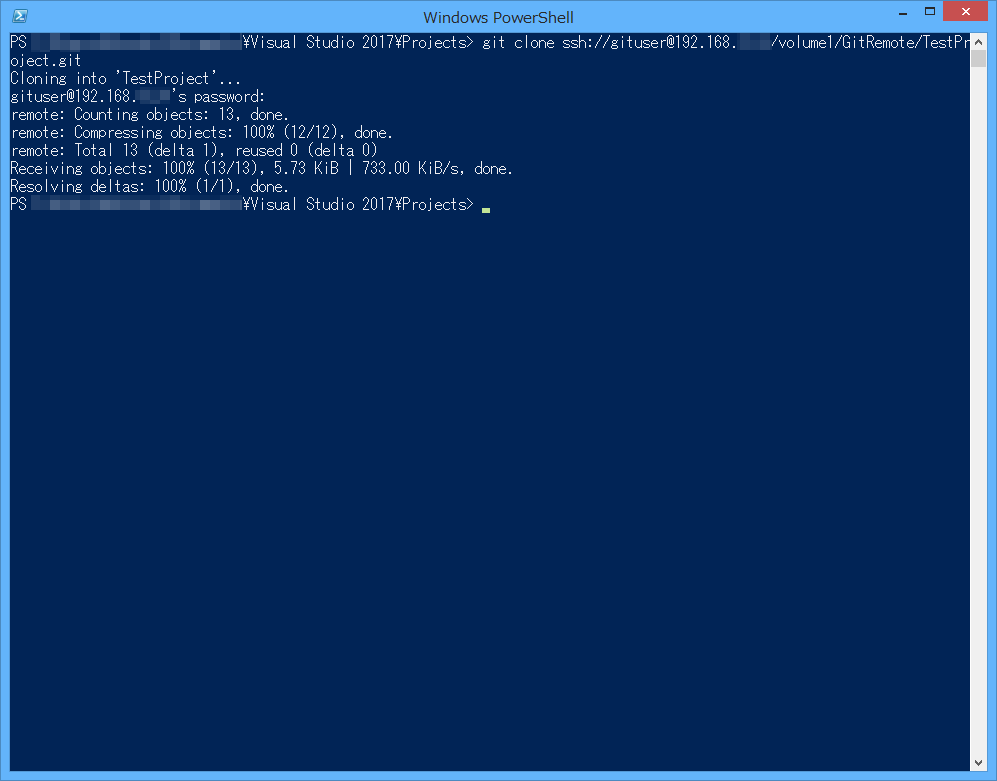
ちゃんとクローンされたプロジェクトが開けました。めでたしめでたし。

pushからの別PCからのpull
せっかく別PCでクローンしたので、こちらで編集してプッシュしてみます。Hello, worldのコードを追加し、「チームエクスプローラー」→「変更」からローカルリポジトリにコミットします。

つづいて「チームエクスプローラー」→「同期」からプッシュします。

パスワードを入力したら無事プッシュされました。

元のPCに戻って、「チームエクスプローラー」→「同期」から今度は「プル」を選択します。

プルが完了したら見事にHello, worldのコードが出現しました。めでたしめでたし。

まとめ
これで無事NASにてGitサーバーを運用し、複数PCでプロジェクトを同期することができるようになりました。Synology NASはadministratorグループに属していないとSSH接続ができないというちょっとアレな仕様があります。まあ、SSHでログインするなんてroot取って何かしらアレなことをしたい人くらいしかいないだろうという想定なんでしょうが、この仕様から、NASを利用する一般ユーザーにNAS上のリポジトリを触らせるのにはセキュリティ上の問題があります。これがどうにかならない限り、ソロGitからは抜け出せないでしょう。
あと、たぶんですけどVisual Studioは公開鍵認証をする方法が無さそうです。せっかくSSHならば公開鍵認証で認証を行って、毎回パスワードを入力しなくてもいいようにしたいんですけどねえ。























